震惊全球AI界!美国斯坦福最火大模型抄袭中国清华开源项目,作者删库跑路
最新消息显示,近日,来自美国斯坦福大学研究团队的一款AI大模型Llama3-V超级火爆,不过很快被网友发现疑似抄袭中国清华大学联合开发的一款多模态模型,并且在网络上直接与该AI大模型作者对质。Llama3-V的作者在一番狡辩之后多少有些心虚,直接在网络上删除了该数据库。
事件的起因要追溯到5月29日,有着斯坦福大学背景的一个研究团队发布了一个名为“Llama3V”的AI模型,号称只要500美元就能基于Llama3训练出一个SOTA多模态模型,效果直接与业界最牛的GPT-4V、Gemini Ultra、Claude Opus看齐,而且体积要小100倍。
这一爆炸性的消息引发全球AI界的关注,毕竟效果又好、价格又便宜是所有开发者的梦想。
值得注意的是,该AI模型开发团队包括Mustafa Aljaddery、Aksh Garg、Siddharth Sharma等人,均来自美国斯坦福大学,又有着特斯拉、SpaceX、亚马逊与牛津大学等机构的相关背景经历,更加增加了可信度。
很快,该模型发布的推特帖子浏览量就迅速上升,在HuggingFace上登上首页,成为AI界的火爆事件。
不过没过几天,推特与一些开发论坛上就开始出现怀疑的声音,质疑Llama3V“套壳”中国面壁智能在5月中旬发布的开源多模态小模型MiniCPM-Llama3-V 2.5,且没有在Llama3V中有所提及。
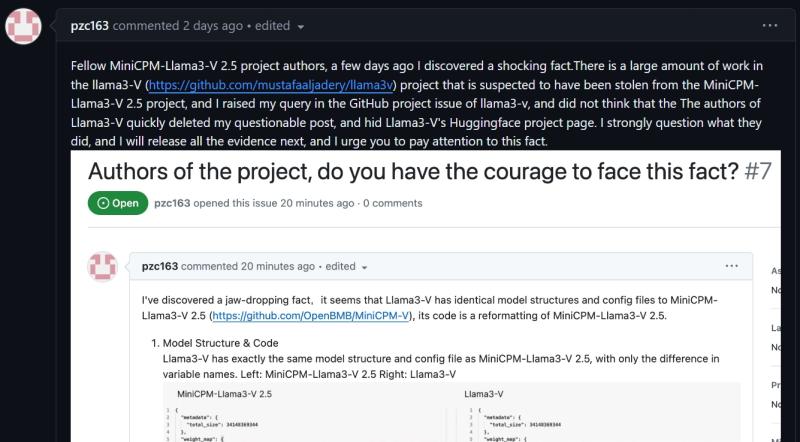
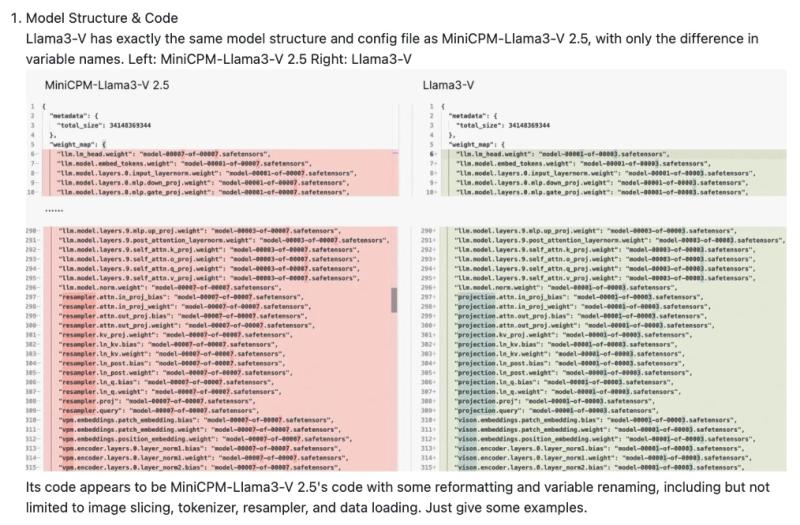
MiniCPM-Llama3-V 2.5由中国清华大学自然语言处理实验室与面壁智能合作开发。
对此,Llama3V团队回复称,他们“只是使用了MiniCPM-Llama3-V 2.5的tokenizer(标记器)”,并宣称在MiniCPM-Llama3-V 2.5发布前就已经开始研究。
随后,面壁智能团队通过测试,发现Llama3V与MiniCPM-Llama3-V 2.5在案例上的表现100%雷同,“正确的地方一模一样,错误的地方也一模一样”。
甚至在清华和面壁团队特别采集和标注、从未对外公开的专有数据处理中,Llama3-V 的表现也非常出色。例如“清华简”是一种非常特殊且罕见的中国战国时期的古文字,而Llama3-V不仅认识“清华简”,在认错字的时候,也和MiniCPM-Llama3-V 2.5表现得一模一样。
至此,推特舆论开始发酵。
面对网友的质疑,Llama3V的作者先是进行了一些自我辩护,但却被网友发现他们似乎并不理解自己的代码,也不太明白抄来的MiniCPM-Llama3-V 2.5架构中的细节。
在无法自圆其说的情况下,Llama3V的作者直接使出终极大招:删数据库,将在HuggingFace上发布的数据库隐藏起来,同时Llama3-V的GitHub项目主页也显示为“404”,无法访问。

之后,Llama3V的作者之一Aksh Garg在网络上发文称,是Mustafa Aljaddery编写了所有代码,而Aksh Garg在看到网络质疑之后要求Mustafa Aljaddery提供原代码,但目前还没有看到有力的原创证据。因此,Aksh Garg向MiniCPM-Llama3-V 2.5的原作者道歉,表示自己盲目地信任了“猪队友”,并且没有验证代码的真实性,他将会更加谨慎和勤奋。

主编精选,篇篇重磅,请点击订阅“邮件订阅”


